Overview of the Pipeline
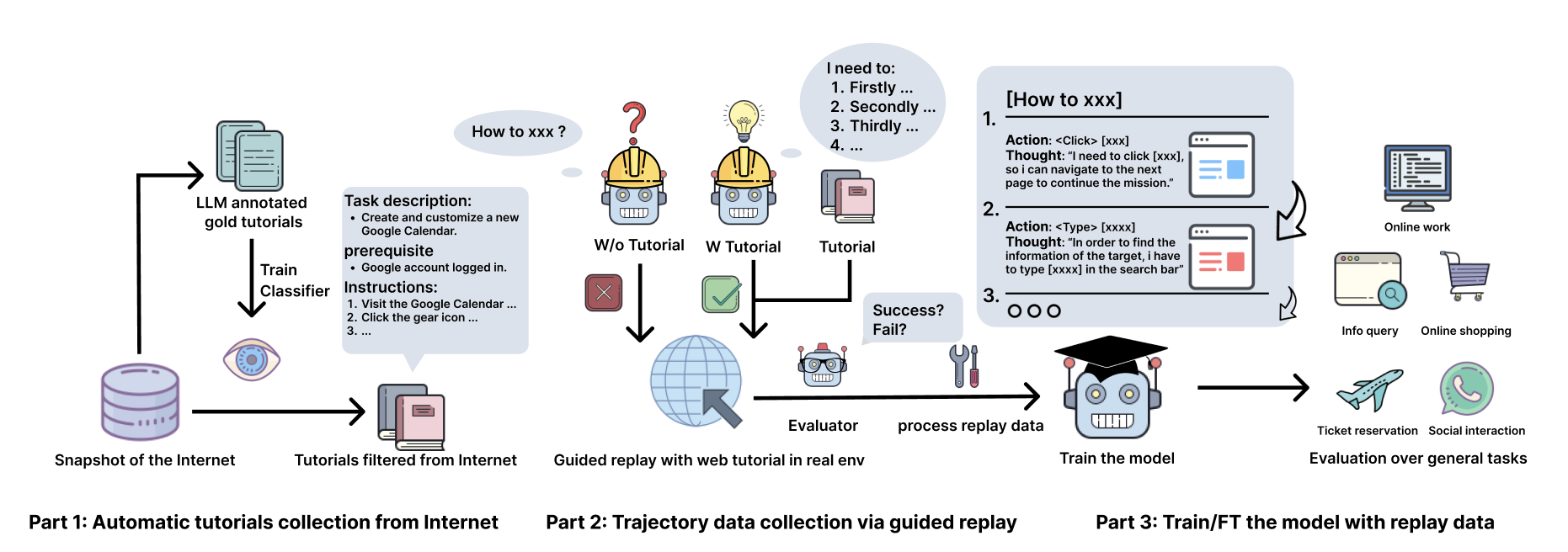
Overview of the AgentTrek Pipeline:
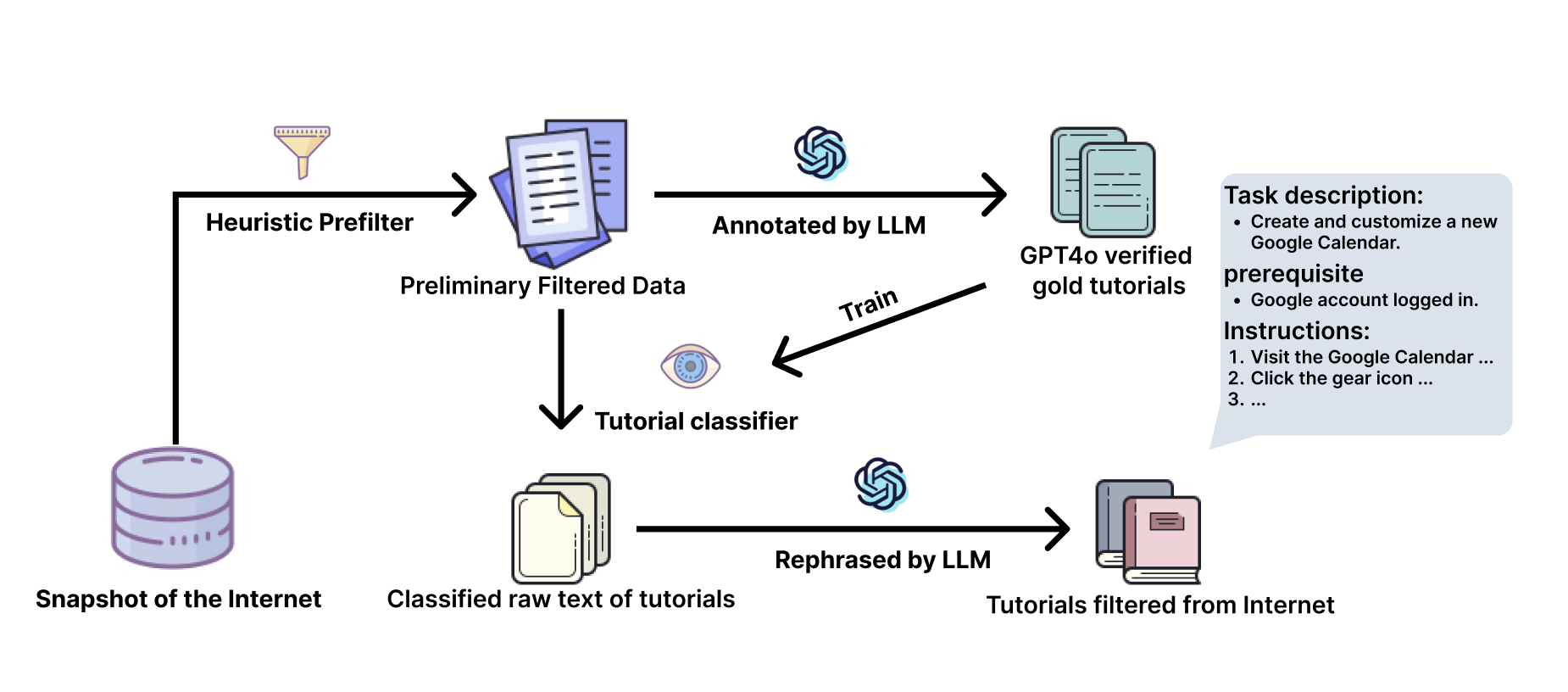
- Automatic Tutorial Collection from the Internet: Tutorial-related data is extracted and filtered from internet sources using heuristic methods and a FastText model. An LLM processes the filtered textual data, transforming it into structured tutorials.
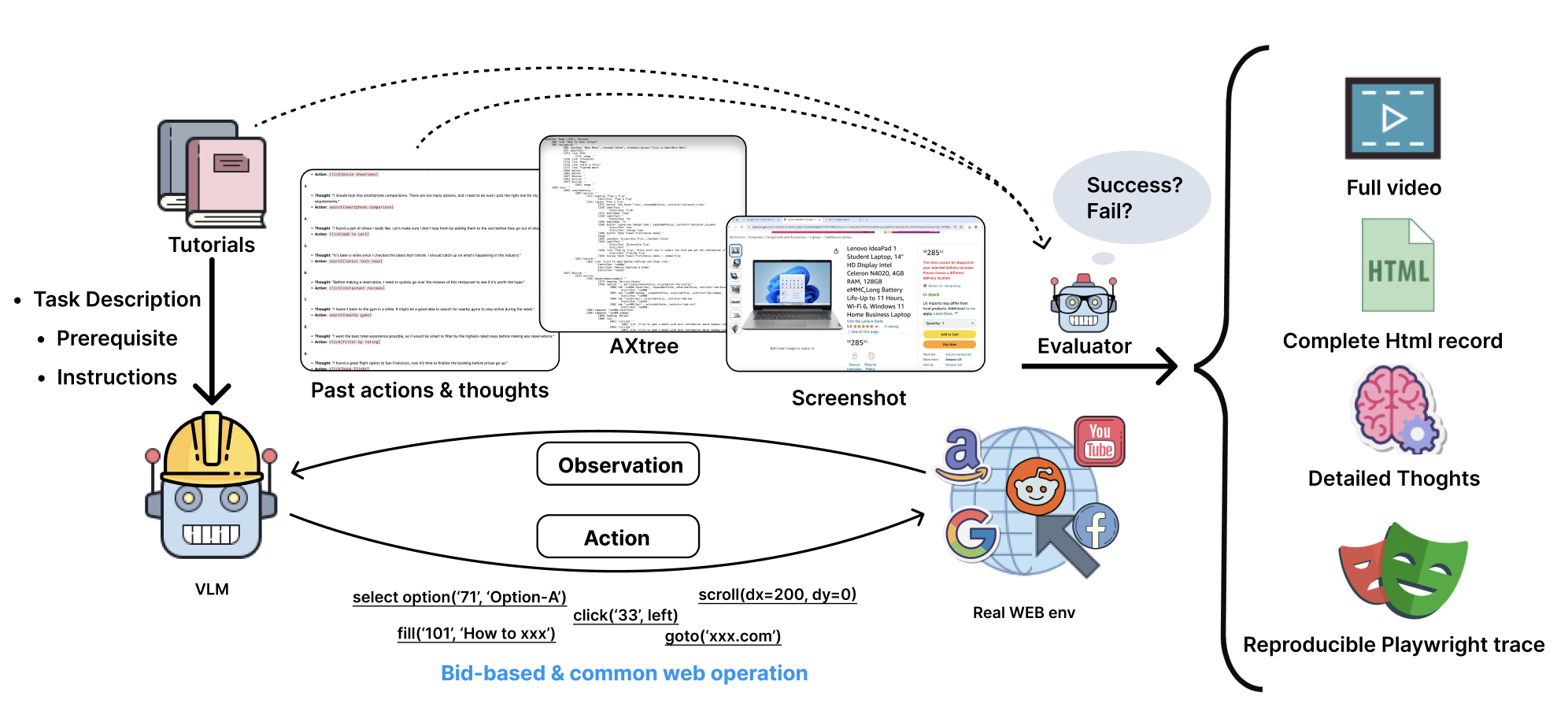
- Trajectory data collection via guided replay: A VLM agent interacts with the real digital environment guided by tutorials, while high-quality trajectory data, including observations, actions, and reasoning, is collected. Another VLM evaluator acts as a judger to further improve the effectiveness of the synthetic dataset.
- Training and fine-tuning with replay data: The collected trajectory data is used to train and fine-tune GUI agent models, which are evaluated on standard agent benchmarks, demonstrating significant improvements.
Guided Replay Demonstrations
|
|
|
|
|
|
|
|
AgentTrek Dataset
AgentTrek is a large-scale multimodal agent trajectory dataset collected from web tutorials. The dataset contains two types of trajectories:
- Text-based Trajectories: We collect text-based trajectories from web tutorials, which contain step-by-step instructions and corresponding HTML observations. These trajectories are used to train pure text-based agents.
- Vision-based Trajectories: We collect vision-based trajectories by executing the text-based trajectories in real digital environments. Each trajectory contains a sequence of screenshots and corresponding actions. These trajectories are used to train pure vision-based agents.
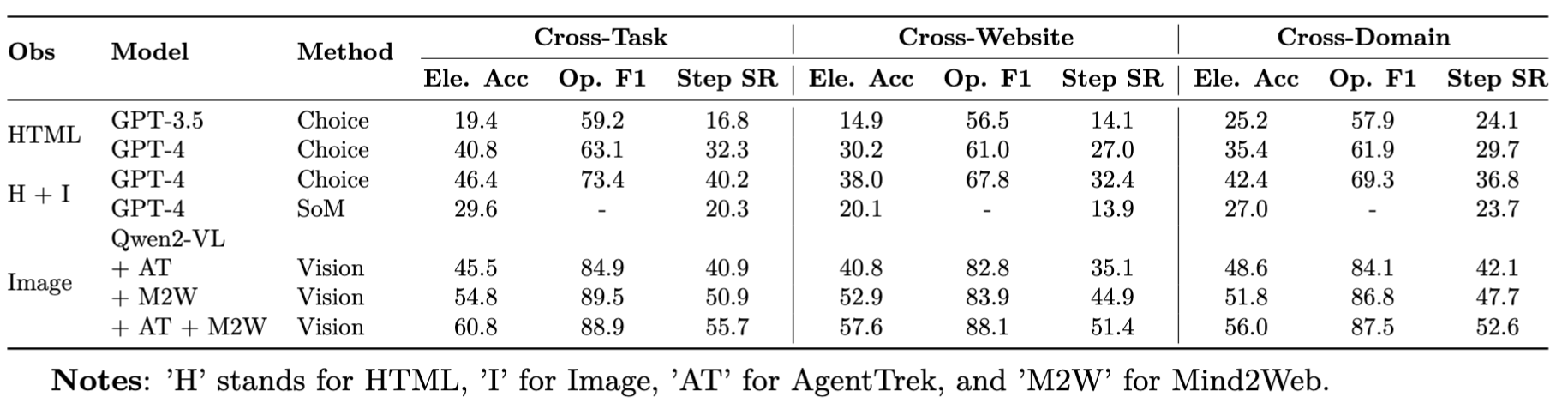
With our AgentTrek pipeline, we generate large-scale trajectory data that excels in three areas. First, the dataset offers extensive diversity, covering multiple domains and task types, and benefiting from internet-sourced tutorials that enhance task execution. Our experiment showed a 230% performance increase when agents followed detailed instructions. Second, the data is gathered from real-world web environments, avoiding the limitations of simulations. Starting with RedPajama, we filtered and processed 23,430 tutorials, producing 10,398 successful trajectories from 127 websites.

The data is comprehensive, capturing high- and low-level task details, including HTML structures, AXTree snapshots, video recordings, and screenshots. This rich data improves the agent's performance on long-horizon tasks, and with a per-trajectory cost of just $0.551, our pipeline offers an efficient, scalable solution for data generation.
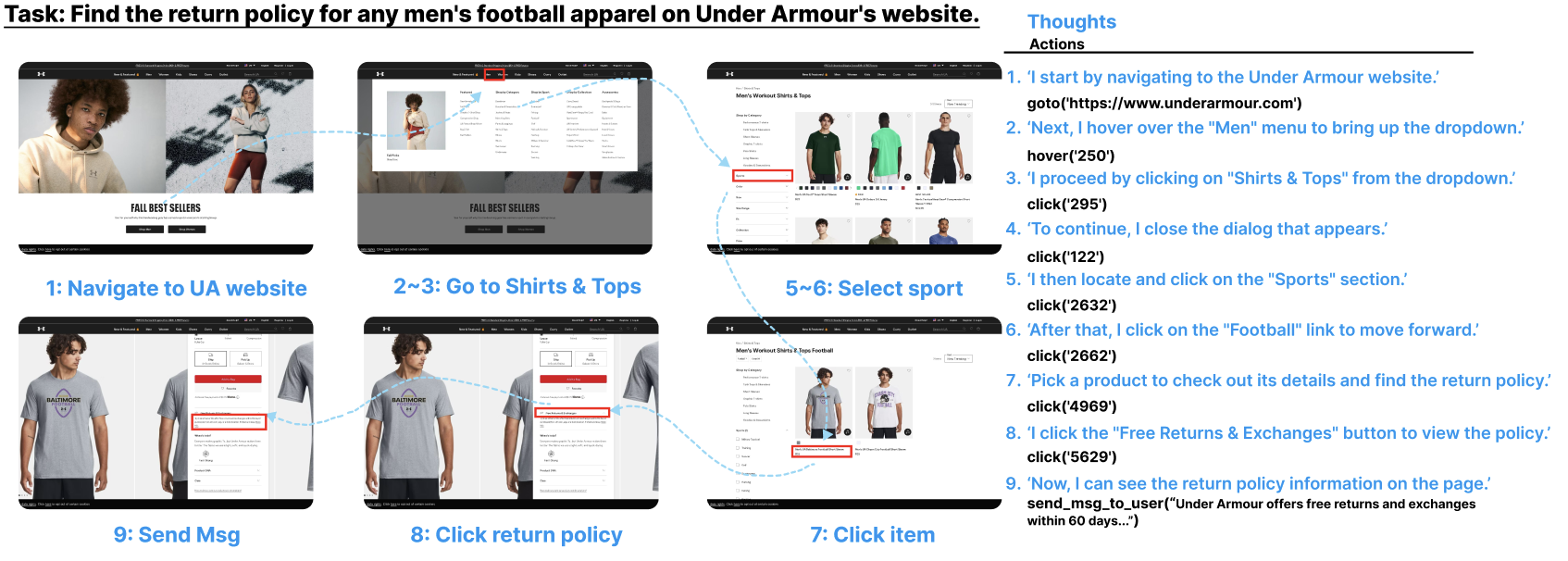
All trajectories are automatically collected and filtered by our pipeline, ensuring high quality and diversity. The dataset will be released soon to facilitate research in GUI agents.
Experiments
AgentTrek collects a large scale of multimodal agent trajectory from the internet. We finetune the VLM model with visual-based trajectory data to obtain a Pure vision-based agent, which is evaluated on Mind2Web and ScreenSpot. We also finetune the LLM model with text-based trajectory data to obtain a Pure text-based agent, which is evaluated on WebArena.
Mind2Web Performance
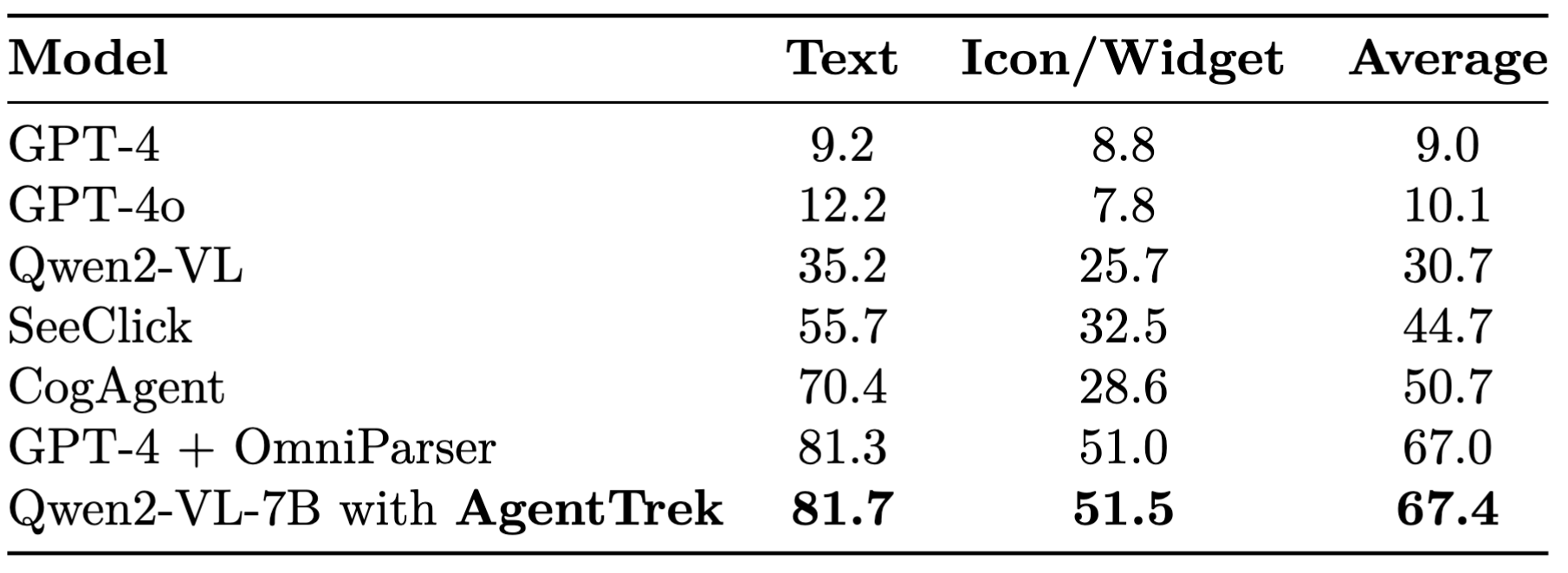
ScreenSpot Grounding Performance
WebArena Evaluation

BibTeX
@article{xu2024agenttrek,
author = {Yiheng Xu and Dunjie Lu and Zhennan Shen and Junli Wang and Zekun Wang and Yuchen Mao and Caiming Xiong and Tao Yu},
title = {AgentTrek: Agent Trajectory Synthesis via Guiding Replay with Web Tutorials},
year={2024},
eprint={2412.09605},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.09605}
}